幹麼標題好似有味…A記你壞啦
推土過後閒想下代打樁,打樁推出後猜想壓路,但壓路機和同期Haswell相比,兩點我有D擔憂
一個是TSX擴展
在支持的軟件中,如果支持和不支持的CPU之間的性能差距會很大,壓路機相比同期Haswell在未來會漸見劣勢?
一個是AVX2
自從知道AVX對x264無大幫助,我就相信A記所說的在現實世界整數使用的比例是比浮點高
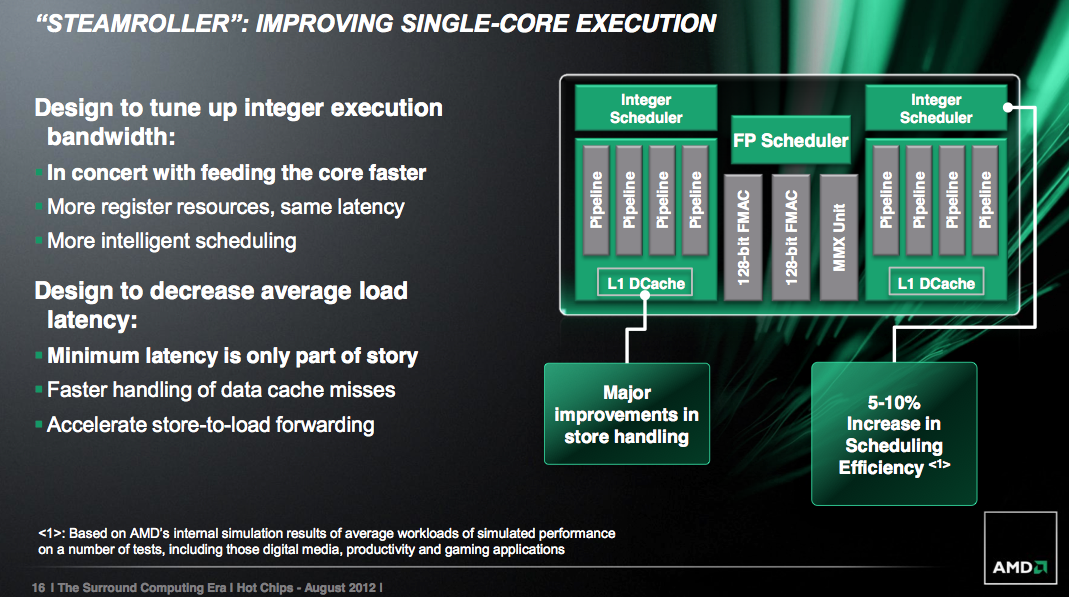
之前的推土/打樁,MMX單元(整數MMX/SSE/AVX)有兩個,即是4模組是有8個128bit SSE/AVX
但壓路機就只有一個,表面是FPU(128bit) FPU(128bit) ALU(不明)
如果那個MMX單元照舊是128bit,其中一個FPU也可以充當ALU使用,而且可以同MMX單元合併為一個256bit SIMD ALU
這樣4模組就有8個128bit整數SSE/AVX,或4個256bit整數AVX
如果是一個不能分開為兩個128bit的256bit MMX單元,而且其中一個FPU可以充當ALU使用
這樣4模組就有8個128bit整數SSE/AVX,或相當6個256bit的整數AVX“4個256bit AVX(全速)+4個256bit AVX(半速)”
同上,但兩個FPU也可以充當ALU使用,兼合併為一個256bit SIMD ALU
這樣4模組就有12個128bit整數SSE/AVX,或8個256bit整數AVX
我真的相信A記所說的,在現實世界中整數使用比例較高
如果最後是4個256bit整數AVX,就要和同期煙條4核1打1,A記1打1打不過煙條,結果明顯
普通x86性能不及煙條,256bit浮點AVX要1打1,整數AVX時候也一樣1打1,煙條還有TSX加持,A記這樣不就全面劣勢?
相當6個256bit的整數AVX
如果線程間有相關性,會不會出現全速要等半速的完成呢?
如果是8個256bit整數AVX
那為什麼不也升級浮點為兩個256bit?
而且壓路機下一代改用自動佈線,因為頻率可能會不高,非常有機會是短管線設計?
壓路機的情況會不會像未代P4,被A記像煙條過渡CORE2那樣是用來拖時間,Excavator後就不由得之前的是黑歷史無出過?
唔怕佢低,只係怕被放飛機
雖然想支持佢,但壓路機賭不賭得過? |
 簡體版
簡體版 訂閱頻道
訂閱頻道 訂閱電子報
訂閱電子報



 發表於 2012-10-24 00:18
|
發表於 2012-10-24 00:18
|