作者: 3ldk 時間: 2025-12-15 11:33 標題: 玩ai買nvidia定amd好D?
暫時聽到兩種完全相反的講法
有一班人話玩ai一定係用nvidia, 因為佢driver好D
另一班人話玩ai最重要係ram多, 咁即係要amd啦, 因為只有amd先有96GB ram
邊個版本先真呢?
作者: usei 時間: 2025-12-15 15:31
睇要用什麼 AI 軟件
作者: lui3271709 時間: 2025-12-15 16:34
n 記..
就例如training lora 咁, amd 我就唔知點做
即可能有, 選擇上都比較少
作者: Comeon 時間: 2025-12-15 16:46
講RAM 多,一定係 Apple unified memory,一部機最大有 512G
而且比 AMD Ryzen AI MAX+395 既 128GB unified memory 仲要快
作者: ckyuen2 時間: 2025-12-15 17:27
nvidia 點會無ram 多嘅款
問題係幾錢啫

作者: a652311279 時間: 2025-12-15 17:38
最好5070以上啦
AMD宜家都系唔得
除非你用Linux?
via HKEPC Reader for Android
作者: 3ldk 時間: 2025-12-15 18:06
最好5070以上啦
AMD宜家都系唔得
除非你用Linux?
via HKEPC Reader for Android
a652311279 發表於 2025-12-15 17:38

即係用linux的話, 就無左driver既問題, 用amd同nvidia已經無分別?
但Linus唔係FAQ nvidia, 話佢D driver唔得咩?
------------
nvidia真係無多ram版本, 就算5090都係得32GB
雖然有中國廠商聲稱改裝 RTX 5090 顯示卡RAM達到128GB的新聞, 但暫時好似都係存疑, 而且都未見過實物
作者: ckyuen2 時間: 2025-12-15 18:35
即係用linux的話, 就無左driver既問題, 用amd同nvidia已經無分別?
但Linus唔係FAQ nvidia, 話佢D driver ...
3ldk 發表於 2025-12-15 18:06
dgx spark 話一日有貨。。。
不過都真係未搵實物嚟見嘅
作者: ckyuen2 時間: 2025-12-15 18:42
仲有rtx pro 6000 都有幾間報價
作者: latali 時間: 2025-12-15 19:27
如果係AI,N 就係5060TI 16G ,5070 以上無超過16G 既都無咩特別優勢,5070 仲有12G,如果係玩AI片,就限左係720P度,要16G 先做到1024P。 A卡主要係少人為佢特別優化,好多AI工具唔支持及就算支持慢好多,比如某D換臉AI工具。
作者: rabbit82047 時間: 2025-12-15 20:27
講真玩 AI 買部 Mac Studio 好過用 Gaming card
作者: 3ldk 時間: 2025-12-15 21:25
講真玩 AI 買部 Mac Studio 好過用 Gaming card
rabbit82047 發表於 2025-12-15 20:27
咁mac可以用512G video ram又確實係幾完美既
但mac的gpu唔係n, 甚至都唔係a, 咁會唔會有ai工具唔支援的問題?
作者: kenken33 時間: 2025-12-15 21:36
本帖最後由 kenken33 於 2025-12-16 01:57 編輯
暫時聽到兩種完全相反的講法
有一班人話玩ai一定係用nvidia, 因為佢driver好D
另一班人話玩ai最重要係ram多 ...
3ldk 發表於 15-12-2025 11:33
AI主力食CUDA,而CUDA係NV獨家野得佢旗下產品先有,第二就係食記憶體頻寬
錢問題姐邊個話nvidia 冇96GB VRAM,你有錢既行多張RTX 6000 pro 96GB X N連起佢都得﹐再有錢咪學AI大企業上H200 4.8 TB/s NVLINK 而且你講AMD個所謂RAM多其實只係普通PC ram來,即使用256-bit相當於四通道ram都係慢GPU 既VRAM幾條街。

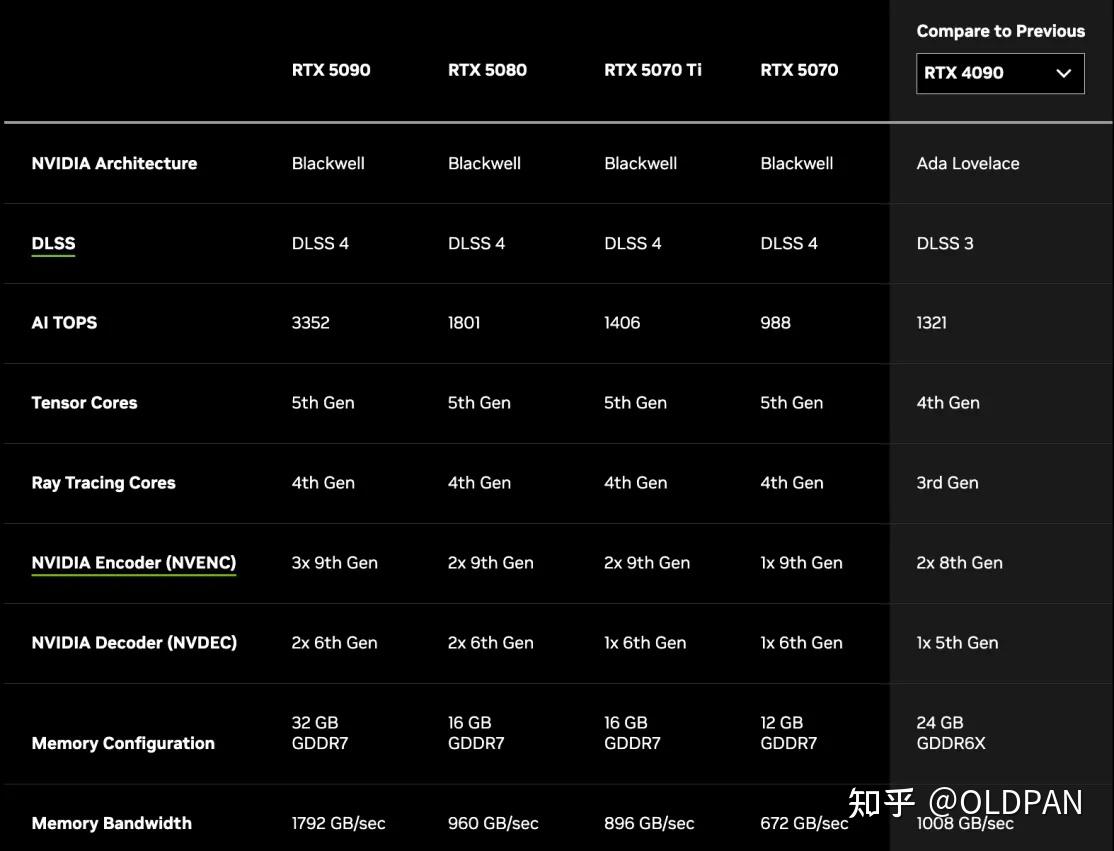
平民搞AI係用mac studio,3萬銀一部96GB 4萬幾 256GB 攻頂8萬512GB,只係M3 Ultra RAM頻寬已經係接近5070TI水平 (819GB/s 記憶體頻寬),過多幾個月出M5 Ultra 頻寬應該過千。AMD果粒野得果2百零頻寬玩手指咩,RTX5090係 1792 GB/s RTX 6000 pro 頻寬同5090差不多就係多VRAM版本既5090
作者: CallPut 時間: 2025-12-29 16:58
回覆 12# 3ldk
Nvdia DGX Spark下月有賣, 好似wellent街鋪一月有Dell Pro Max with GB10賣(DGX Spark), 不過平民AI有咩玩法??講D嚟聽下.....
作者: ki_cat 時間: 2025-12-30 10:03
本帖最後由 ki_cat 於 2025-12-30 12:03 編輯
我唔知理解有無錯,家用級gen圖,vram同system ram無好多人想像中差咁遠.你搵係同類既會爆vram,除左load果下,隨時快過縮ram版q4.
瓶頸應該唔係完全係system ram度.ddr5 6000來講.
llm就真係差好遠.
via HKEPC IR 5.1.14 - Android(5.1.2F)
作者: s84292 時間: 2025-12-30 11:16
即係用linux的話, 就無左driver既問題, 用amd同nvidia已經無分別?
但Linus唔係FAQ nvidia, 話佢D driver ...
3ldk 發表於 2025-12-15 10:06
邊度冇多RAM版本?
NVIDIA RTX PRO™ 6000 咪96GB
NVIDIA RTX PRO™ 5000 咪48GB
香港都有得買
仲有NVIDIA DGX Spark 128GB ,DELL ASUS HP都有賣,都係3萬幾ONLY
作者: ponghk 時間: 2025-12-30 11:19
咁mac可以用512G video ram又確實係幾完美既
但mac的gpu唔係n, 甚至都唔係a, 咁會唔會有ai工具唔支援的問 ...
3ldk 發表於 2025-12-15 09:25 PM
我自己行 NV, 其他唔係太熟. 以我所知, 行 llm 即 DeepSeek 果類. 問佢問題, 叫佢寫文做分析. NV, AMD, Mac 都行到. 如果 gen 圖+片 99% 買 NV, Mac 都玩到少少但差距太大, AMD GPU 就算行到你最好都當佢夾硬黎.
因為唔係個個人都只係用黎 gen A 圖 gen A 片, 更加多既人行 llm 平時係做日常和工作上的分析.
作者: ponghk 時間: 2025-12-30 11:32
本帖最後由 ponghk 於 2025-12-30 11:37 編輯
回覆 3ldk
Nvdia DGX Spark下月有賣, 好似wellent街鋪一月有Dell Pro Max with GB10賣(DGX Spark), 不 ...
CallPut 發表於 2025-12-29 04:58 PM
我有諗過入手 DGX Spark. 而家都有 Asus, MSI 既 DGX Spark 賣. 下個月有 Dell 版? 但佢得5070 算力, 而且得 128GB VRAM+OS RAM, 依個價有少少唔上唔落, 因為 load 大既 llm 得 128 又擺唔入. 如果自己想 fine tune 或者 train video lora 都未必夠 ram. 買兩部行 cluster 不如比多少少入 RTX 5000 Pro 72GB 或 RTX Pro 6000 96GB. 我都係一般應用, 二三萬都極限.
係喎. Dell Pro Max GB10 FCM1253 128Gb 2Tb-SSD Graphic AI 桌上型電腦
$31,990
作者: ponghk 時間: 2025-12-30 12:13
我唔知理解有無錯,gen圖,vram同system ram無好多人想像中差咁遠.你搵係同類既會爆vram,除左load果下,隨時快 ...
ki_cat 發表於 2025-12-30 10:03 AM
llm 好睇 ram 速度, 佢要係一個好大 database 搵資料. gen 圖 gen 片主要睇 GPU 算力, 有 24~32GB VRAM 足夠. 係 gen 720p 片先要多 vram + ram, 暫時地球上本機部署 gen 片最好得 wan 2.2, 我睇過晒 4090 24GB, 4090 48GB 同 RTX Pro 6000 96GB 行 wan 2.2, 感覺上同 5090 32GB 差唔多, 4090 48GB 仲慢過 5090 32GB.
我覺得 wan 2.2 似乎對 over 32GB VRAM 無優化就真. 始終 2.2 只係 2.1 小改版, 而 2.1 已經今年二月既事. wan 2.5/2.6 係大改 ver, 但唔肯放 open sources.
4090 48GB 只比 4090 24GB 快 14%
5090 32GB 比 4090 48GB 快 25%(比 4090 24GB 快 35%)
RTX 6000 Pro 96GB 比 5090 32GB 快 32%
作者: CallPut 時間: 2025-12-30 19:05
就用嚟Gen圖玩多幾次就厭....有無更好玩玩法或者實用玩法分享下??
作者: lolo_hk 時間: 2025-12-30 20:34
N記和A記消費級卡我都玩過
現時AI tool 好多都係 based on N記 CUDA, A記 official AI app 真係好少.
My experience, 玩 LLM ollama N記卡 8G VRAM 起跳, 玩Gen 圖 Gen 片 comfyui N記卡 16G VRAM 起跳
作者: ki_cat 時間: 2025-12-30 20:39
我有諗過入手 DGX Spark. 而家都有 Asus, MSI 既 DGX Spark 賣. 下個月有 Dell 版? 但佢得5070 算力, ...
ponghk 發表於 2025-12-30 11:32
玩法唔同既,一張係咭,一個係慳電機仔.
via HKEPC IR 5.1.14 - Android(5.1.2F)
作者: ki_cat 時間: 2025-12-30 20:43
本帖最後由 ki_cat 於 2025-12-30 20:44 編輯
N記和A記消費級卡我都玩過
現時AI tool 好多都係 based on N記 CUDA, A記 official AI app 真係好少.
My e ...
lolo_hk 發表於 2025-12-30 20:34
ollama唔support vulkan,amd用llama.cpp比較好.
via HKEPC IR 5.1.14 - Android(5.1.2F)
作者: ponghk 時間: 2025-12-30 22:02
就用嚟Gen圖玩多幾次就厭....有無更好玩玩法或者實用玩法分享下??
CallPut 發表於 2025-12-30 07:05 PM
Wan 2.2 本身限制咗好多 motion 同動作, 用其他大神出既改版, 啲片好玩好多。
via HKEPC Reader for Android
作者: 3ldk 時間: 2025-12-31 10:31
llm 好睇 ram 速度, 佢要係一個好大 database 搵資料. gen 圖 gen 片主要睇 GPU 算力, 有 24~32GB VRAM ...
ponghk 發表於 2025-12-30 12:13
咁寫code係ram定gpu?
作者: POE100 時間: 2025-12-31 16:59
玩AI 睇你點"玩"
你用AI SOFTWARE 同你會做Fine tuning又唔同
CUDA差唔多喺AI既基本....即喺N CARD
AMD唔喺話唔得, 不過中間可能比較多卡位
睇下市佔率就有答案
最緊要RAM多喺真....但喺5090 32GB定喺去到PRO-6000 96GB 就要睇你口袋
如果你一張卡都無...我覺得最少都買16GB起標 , 唔好買8GB, 好快唔夠用
作者: ken9999 時間: 2025-12-31 20:18
5090 32GB個價夠買兩張RTX PRO 4000返黎行SLI
作者: ki_cat 時間: 2025-12-31 20:21
本帖最後由 ki_cat 於 2025-12-31 20:30 編輯
咁寫code係ram定gpu?
3ldk 發表於 2025-12-31 10:31
CODE係LLM主要睇RAM量同速度
制圖同片算法唔同,家用顯卡速度連SYSTEM RAM都夠做
今日係REDDIT見到有人話5070TI 整片快過3090
https://www.reddit.com/r/comfyui ... 0s/comment/nws7xiv/
下面 5080 爆唔爆VRAM係零分別.信不信由你
[attach]2510391[/attach]
作者: ponghk 時間: 2026-1-1 04:28
本帖最後由 ponghk 於 2026-1-1 12:56 編輯
5090 32GB個價夠買兩張RTX PRO 4000返黎行SLI
ken9999 發表於 2025-12-31 08:18 PM
..........
作者: ponghk 時間: 2026-1-1 04:48
本帖最後由 ponghk 於 2026-1-1 04:50 編輯
CODE係LLM主要睇RAM量同速度
制圖同片算法唔同,家用顯卡速度連SYSTEM RAM都夠做
今日係REDDIT見到有人 ...
ki_cat 發表於 2025-12-31 08:21 PM
5080 爆 VRAM 果到唔係太可信. 睇過其他 wan 2.2 720p 爆 VRAM 評測 4090 48GB 比 4090 24GB 14%, RTX 6000 Pro 96GB 比 5090 32GB 快 32%.
reddit 更新 720p 測試, 都話 3090 24GB 比 5070Ti 快好多好多. 佢測試應該係 BF16, 咁當然假如 5070TI 行 FP8/FP6/FP4 又未必輸太多既, 只係畫質有所下降.
1280x1280 x 81 3090(1220秒) 5070Ti(5551秒)
UPDATE: I added a 1280x1280 in there to see what happens when I really push the memory usage and sure enough at that point the 3090 won by a significant margin.
作者: ponghk 時間: 2026-1-1 05:39
本帖最後由 ponghk 於 2026-1-1 13:17 編輯
咁寫code係ram定gpu?
3ldk 發表於 2025-12-31 10:31 AM
寫 code 唔係 gen 圖同片, 主要睇 ram 容量同速度. Desktop 96/128GB basic, 最好有 192/256GB. 512GB 以上要 ECC ram + workstation/server 底版行 Xeon 同 Threadripper. GPU 算力唔係無用, 但 ram 唔夠你都 load 唔入個 model; load 得入大 model, GPU 太雞又確實慢, 玩到 192/256GB 用 3060 慢慢計數, 個 result 等到天光, GPU 算力也要.
https://www.linkedin.com/posts/%E4%B8%AD%E5%96%AC-%E6%B1%9F-52004653_github-fission-aiopenspec-spec-driven-activity-7388230180248457216-zAob/?originalSubdomain=cn
AI 寫 code 唔熟, 頭先笠過吓有隻叫 OpenSpec 寫 code 助理, 好似幾有用.
比較抵玩 Mac Studio 256GB $43999 最平, Mac Stuido 512GB $73249 最平. Mac default 用 66% ram 作 VRAM 可以打 sudo command 改, 可以 set 90% 都得. 但 Mac 都係少好多其他野玩. 啲人鐘意行兩張 NV card, 四張卡又係要 workstation/server 底版.
作者: ponghk 時間: 2026-1-1 06:02
玩AI 睇你點"玩"
你用AI SOFTWARE 同你會做Fine tuning又唔同
CUDA差唔多喺AI既基本....即喺N CARD
AMD唔喺 ...
POE100 發表於 2025-12-31 04:59 PM
16GB VRAM 其實勵強, 就咁行咩都唔玩就夠. 假如係 comfyui 加大量 nodes 都會 oom, 只能用 FP8 或 gguf. 所以 24/32GB 先正式叫夠, 16 要優化.
作者: ki_cat 時間: 2026-1-1 12:03
本帖最後由 ki_cat 於 2026-1-1 12:24 編輯
5080 爆 VRAM 果到唔係太可信. 睇過其他 wan 2.2 720p 爆 VRAM 評測 4090 48GB 比 4090 24GB 14%, RTX 6 ...
ponghk 發表於 2026-1-1 04:48
5080我覺得佢係CUT左CILP同LOAD入果PART.淨計DIFFUSION.AI讀指示都要LLM.
作者: ken9999 時間: 2026-1-1 12:50
Pro 4000 平過 5090D V2, 你指 RTX Pro 5000? 都係一張半 5090 或者唔夠張半, 但 Pro 5000 算力都唔算特別快, 大約等如一張 4090D 48GB, 但重點得 300w.
ponghk 發表於 2026-1-1 04:28
我都寫明係5090 32GB你係都要攞張得24GB既黎講
作者: ponghk 時間: 2026-1-1 12:58
我都寫明係5090 32GB你係都要攞張得24GB既黎講
ken9999 發表於 2026-1-1 12:50 PM
你對. 我睇錯咗. 尋晚倒數, 半夜先返到屋企, 可能恰眼訓.
作者: ponghk 時間: 2026-1-1 15:04
5080我覺得佢係CUT左CILP同LOAD入果PART.淨計DIFFUSION.AI讀指示都要LLM.
ki_cat 發表於 2026-1-1 12:03 PM
有啲奇怪. Wan 2.2 FP16 720p 點會用得 10GB VRAM? 但wan 2.2 十分適合 blackwell 架構, 係 VRAM 唔大咬下, 5080 我睇過其他人做 test 拍得住 4090D. 所以行 wan2.2 我都幾建議用 5 系 card, 不過 4080S 32GB 同 4090 48GB 魔改確實係吸引既.
作者: s84292 時間: 2026-1-2 00:10
寫 code 唔係 gen 圖同片, 主要睇 ram 容量同速度. Desktop 96/128GB basic, 最好有 192/256GB. 512GB ...
ponghk 發表於 2025-12-31 21:39
寫code 呢d 直接用api好過,自己起又貴又食電又慢,成本根本唔化算
作者: ponghk 時間: 2026-1-2 00:21
寫code 呢d 直接用api好過,自己起又貴又食電又慢,成本根本唔化算
s84292 發表於 2026-1-2 12:10 AM
都係既。而家好多人 gen 片 gen 圖都課金 API. 我本身手持 512GB ram(大多數 DDR5), 先會成日係到諗本機部署。。。。
via HKEPC Reader for Android
作者: latali 時間: 2026-1-2 07:09
本帖最後由 latali 於 2026-1-1 23:22 編輯
有啲奇怪. Wan 2.2 FP16 720p 點會用得 10GB VRAM? 但wan 2.2 十分適合 blackwell 架構, 係 VRAM 唔大咬 ...
ponghk 發表於 2026-1-1 07:04
主要係用 memory block swap, 或者mmgp技術,將本來應該全部放係VRAM處理既野分開好多舊先存留去RAM度,然後VRAM處理好既部份轉去RAM度,再由RAM將剩餘分次傳去VRAM處理,最後合迸埋一齊,咁就唔會太易OOM。缺點係需要更多時間,但就比爆VRAM快好多。 個人試既流程,12g vram剛剛好gen5秒81frames 片865X640或765X765用盡又唔爆。而要達到720p就要降低秒數,所以咁樣呢個方式最好都係要有16g 以上既卡。
作者: singlag 時間: 2026-1-3 16:07
幾皮野買套番來行 ai llm / gen 圖,其實唔係買 api 個效果仲好咩,local llm 完全唔係 claude /gemini3 個水平
Gen 圖/片除非要 gen nsfw, 否則都係近似,nsfw 直接租 cloud 再起,按用量收費唔會更抵 ?
via HKEPC Reader for Android
作者: latali 時間: 2026-1-3 18:43
本帖最後由 latali 於 2026-1-3 10:47 編輯
幾皮野買套番來行 ai llm / gen 圖,其實唔係買 api 個效果仲好咩,local llm 完全唔係 claude /gemini3 個 ...
singlag 發表於 2026-1-3 08:07
其實睇你有無私人野要做,有D平台唔比出18禁,擦邊(比如走光,布很少的)等等,無要求既豆包免費已經好好用。
GEN 片租卡效果一定更好,可以GEN 長片配埋音,小白都識用,一分錢一分貨。如果平時係會打機個D,買左5090,玩AI都只係順便。
作者: F19921111 時間: 2026-1-4 15:00
N記,優化通常好D
作者: ki_cat 時間: 2026-1-5 11:26
本帖最後由 ki_cat 於 2026-1-5 11:31 編輯
幾皮野買套番來行 ai llm / gen 圖,其實唔係買 api 個效果仲好咩,local llm 完全唔係 claude /gemini3 個 ...
singlag 發表於 2026-1-3 16:07
llm開源係玩角色扮演,唔駛準.
via HKEPC IR 5.1.14 - Android(5.1.2F)
作者: thereus 時間: 2026-1-5 11:31
以車來做簡單比喻:
NV:自動波
AMD:棍波
作者: ponghk 時間: 2026-1-6 17:07
本帖最後由 ponghk 於 2026-1-7 00:53 編輯
幾皮野買套番來行 ai llm / gen 圖,其實唔係買 api 個效果仲好咩,local llm 完全唔係 claude /gemini3 個 ...
singlag 發表於 2026-1-3 04:07 PM
llm 行 api 係比較化算, 因為真係無咁多 ram. gen 圖+片近半年 open sources 追得好貼, 某啲功能好過 api. Qwen image 2512 同 Wan 2.2 已經好唔錯. Wan 2.2 加大量 lora 同埋用大神出既改版, 效果唔錯. 各大 api 要求愈來愈嚴, 少少色色已經唔俾, 唔好話真係 nsfw. 我先前都課金好多錢, 但 gen 圖+片消耗金錢始終多, 長遠用 api/cloud 反而唔化算. 不過家吓 ram, ssd, gpu 狂昇價就難講既.
https://huggingface.co/Lightricks/LTX-2
今日最新出 LTX-2 open sources, 已經超越市面 API. 本機運行直出 4K 50fps 最長 20 秒, 有聲有音樂. 宣稱比 Wan 2.2 運行快, 我見有人用 5090 32GB 試咗話幾快. 佢 output 好似得 1080P/2K/4K, 暫時最少要 32GB VRAM 先行到. 16GB VRAM heavy tweaking 有人都行到 720p 5秒 24fps, 但佢個 NV4 就只支援 Blackwell.
https://ltx.io/model/model-blog/prompting-guide-for-ltx-2
Demo 片同埋 prompt
作者: singlag 時間: 2026-1-7 03:30
回復 45 #ponghk
Gen 片我舊時只玩過wan2.1, 效果好似同 sora 果 d 有距離,可能我唔識攪,加上得16gb vram
via HKEPC Reader for Android
作者: s84292 時間: 2026-1-7 08:48
幾皮野買套番來行 ai llm / gen 圖,其實唔係買 api 個效果仲好咩,local llm 完全唔係 claude /gemini3 個 ...
singlag 發表於 2026-1-3 08:07
gen 圖,我一張5090 一日gen 過千張,8秒一張咁run
計API一定好甘
作者: ki_cat 時間: 2026-1-7 08:55
本帖最後由 ki_cat 於 2026-1-7 09:38 編輯
llm 行 api 係比較化算, 因為真係無咁多 ram. gen 圖+片近半年 open sources 追得好貼, 某啲功能好過 api ...
ponghk 發表於 2026-1-6 17:07
剛剛望reddit,有人講玩到連3070 notebook 8 +64都輕鬆出720p.
今晚收工可以試下玩.
https://www.reddit.com/r/StableD ... e_8gb_vram_amazing/
via HKEPC IR 5.1.14 - Android(5.1.2F)
作者: 口o口 時間: 2026-1-7 21:38
gen 圖,我一張5090 一日gen 過千張,8秒一張咁run
計API一定好甘
s84292 發表於 2026-1-7 08:48
電費都好甘...
作者: ki_cat 時間: 2026-1-8 11:56
https://blog.comfy.org/p/official-amd-rocm-support-arrives
COMFYUI早兩日正式支援,ROCM,我無,有興趣試下
作者: thereus 時間: 2026-1-8 21:35
COMFYUI早兩日正式支援,ROCM,我無,有興趣試下
ki_cat 發表於 2026-1-8 11:56
其實之前都已經得, 尼到都有師兄分享過 ,
係要自己逐樣野裝. 效果都唔錯.
今次終於 Official Support ROCm
作者: cngaiyin 時間: 2026-1-17 23:55
試咗COMFYUI只能說用起來非常爽快,方便安裝,不用再像以前弄這弄那
(利申:7800XT)